Linear Mode Connectivity Barriers
are Logit Linearization Gaps
Under Review
Abstract
We give an exact pointwise decomposition of the cross-entropy barrier on the linear chord between any two classifiers. Writing $E(\alpha;x)$ for the per-example logit linearization error along $\gamma(\alpha)=(1{-}\alpha)\theta_A+\alpha\theta_B$,
where $D$ is the LSE deviation, $J\ge 0$ an endpoint Jensen gap, and $E_y$ the true-label coordinate of $E$. The decomposition is purely algebraic—no Hessian, no projection, no alignment—and shows that the logit linearization error $E$ is the unique channel through which any barrier arises. Two one-line corollaries from LSE convexity bound $B_{\mathrm{lin}}$ by forward-pass functionals of $E$. We verify the decomposition on 36 endpoint pairs across six architecture classes (including ViT-Base and GPT-2) and demonstrate two mechanistic consequences: Hungarian weight matching reduces $B_{\mathrm{lin}}$ precisely because it shrinks $E$, and wide networks have smaller normalized barriers because $E$ vanishes in the near-linear regime. The decomposition also enables per-example barrier attribution: the top 35% of examples contribute half the raw barrier, and alignment makes the residual gap more concentrated while reshuffling which classes dominate it.
Key Results
The decomposition holds exactly across six architecture classes, 36 endpoint pairs, and over 2.5 orders of magnitude in barrier scale.
(exact to 10−4)
across 6 architectures
Hungarian alignment
in width sweep
Core Intuition
When a network is linear in its parameters, logits interpolate linearly and the barrier is zero. When it is nonlinear, the logit trajectory bows away from linear interpolation, producing $E\neq 0$—and the LSE convexity gap drives the barrier.
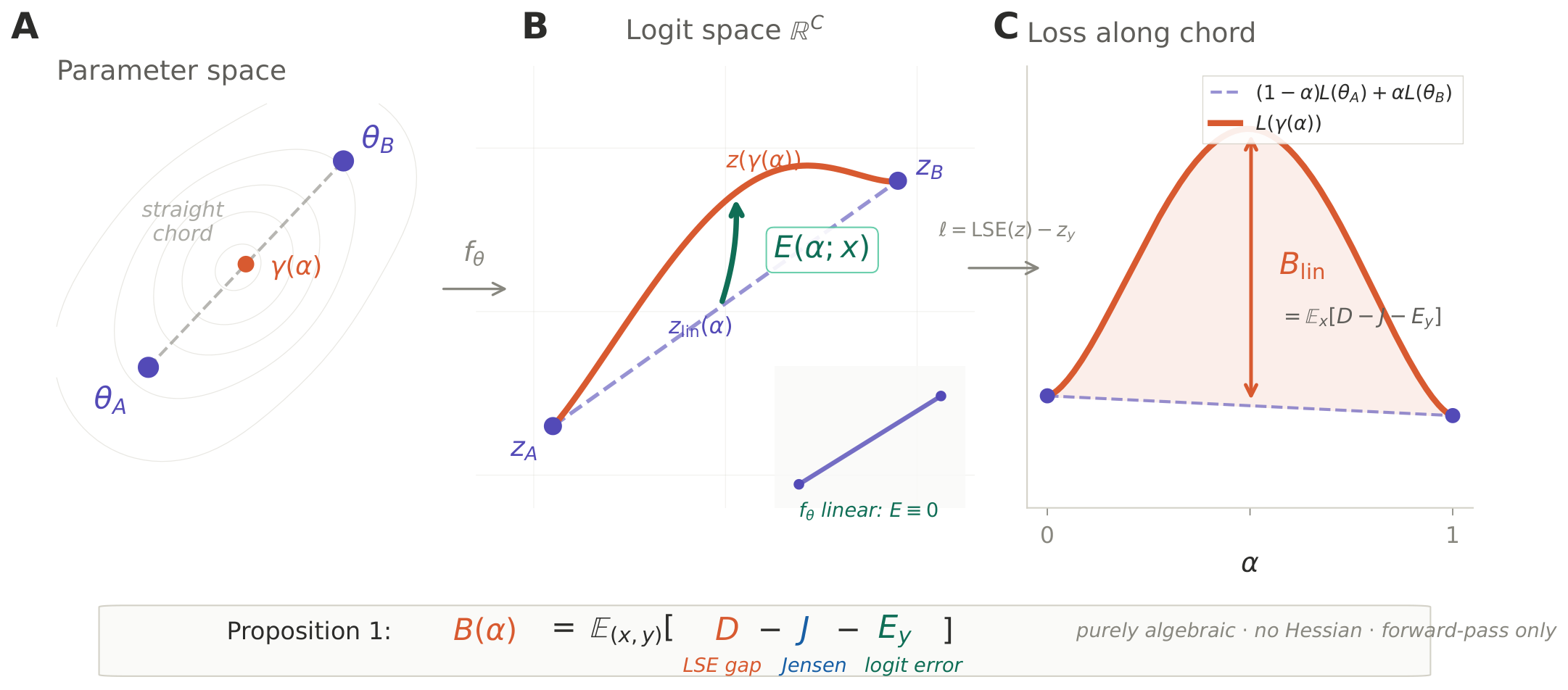
The Decomposition Identity
The barrier decomposes into three forward-pass terms. No Hessian, no alignment, no projection is used. The identity holds as an algebraic equality—verified to $10^{-4}$ on every pair.
$\displaystyle B(\alpha) = \mathbb{E}_{(x,y)}\!\bigl[\,D(\alpha;x) - J(\alpha;x) - E_y(\alpha;x)\,\bigr]$
where $D = \mathrm{LSE}(z_\gamma) - \mathrm{LSE}(z_{\mathrm{lin}})$, $J = (1{-}\alpha)\mathrm{LSE}(z_A) + \alpha\,\mathrm{LSE}(z_B) - \mathrm{LSE}(z_{\mathrm{lin}}) \ge 0$, $E_y = [z_\gamma - z_{\mathrm{lin}}]_y$.
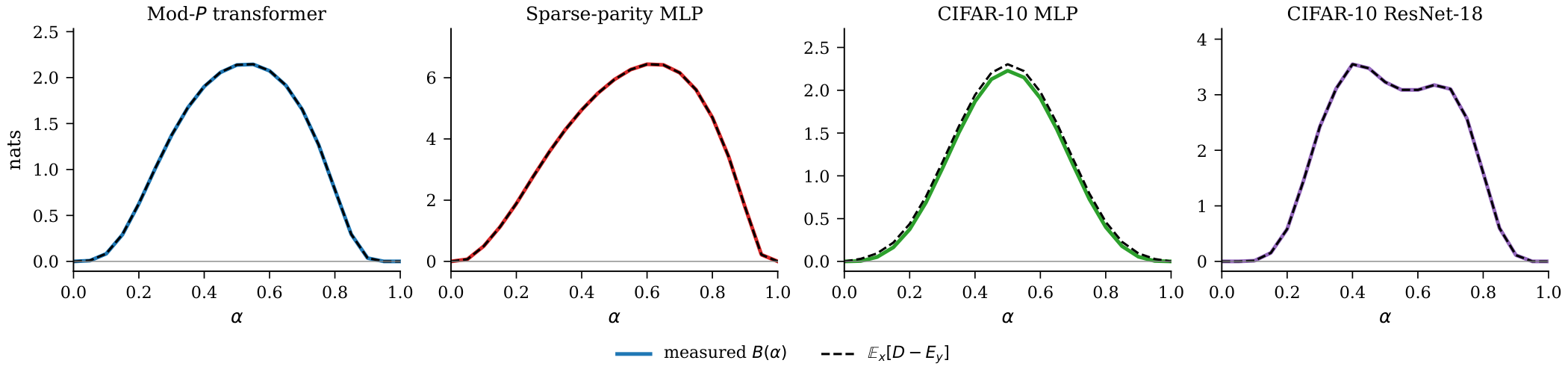
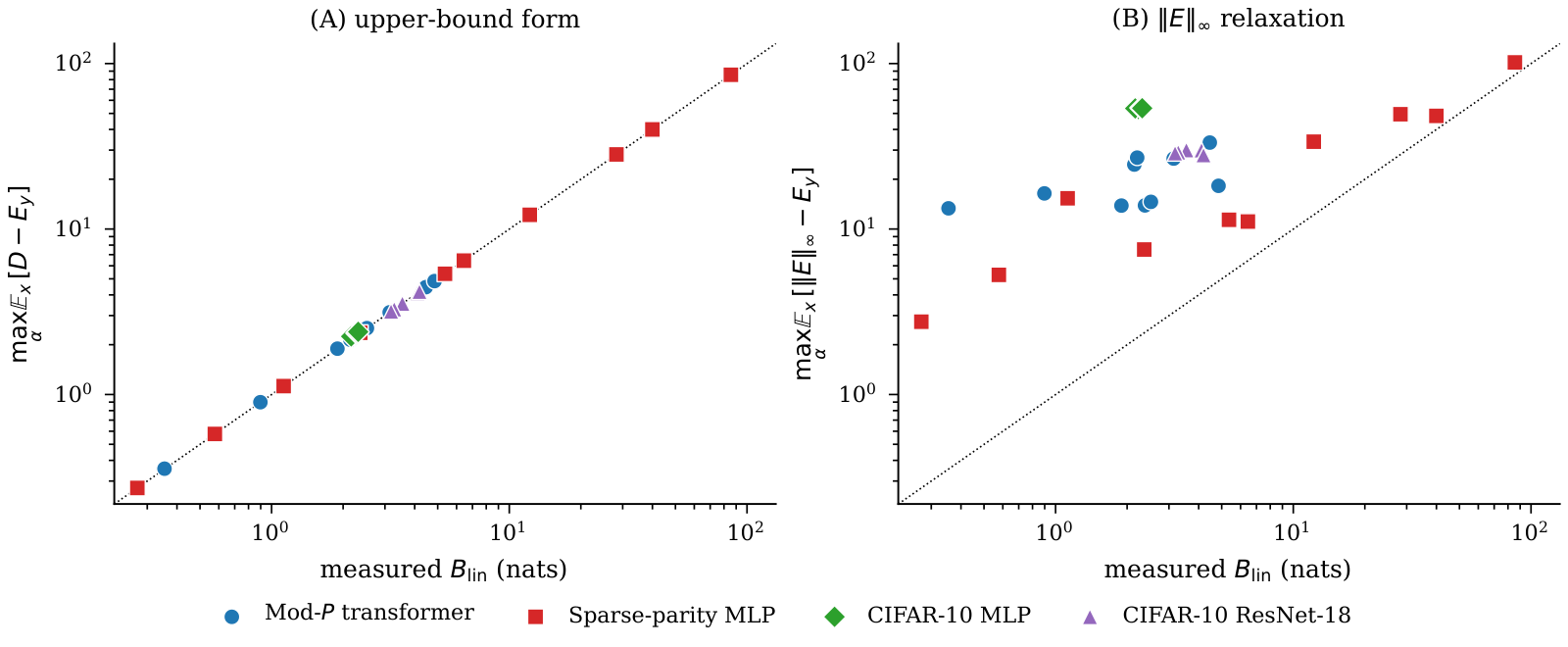
Universality Across Architectures
Tested on six architecture classes spanning vision and language: mod-$P$ transformers, sparse-parity MLPs, CIFAR-10 MLPs, ResNet-18, ViT-Base (85M), and GPT-2 (124M).
| Architecture | Pairs | $B_{\mathrm{lin}}$ range (nats) | Identity ratio | $\|E\|_\infty$ ratio |
|---|---|---|---|---|
| Mod-$P$ Transformer | 10 | 0.35 – 4.85 | 1.0002 – 1.0056 | 3.8 – 37.7× |
| Sparse-parity MLP | 10 | 0.27 – 85.6 | 0.9998 – 1.0007 | 1.2 – 13.6× |
| CIFAR-10 MLP | 5 | 2.16 – 2.31 | 1.028 – 1.039 | 23.2 – 24.8× |
| CIFAR-10 ResNet-18 | 5 | 3.18 – 4.19 | 1.0000 | 6.7 – 9.0× |
| Tiny ImageNet ViT-Base | 3 | 0.25 – 0.33 | 1.186 – 1.255 | 9.8 – 11.9× |
| WikiText-2 GPT-2 (124M) | 3 | 2.06 – 2.26 | 1.0000 | 5.1 – 5.4× |
Permutation Alignment Shrinks $E$
Hungarian weight matching reduces the barrier by 3.18× on CIFAR-10 MLPs. The decomposition tracks both sides: alignment works precisely because it shrinks the logit linearization error $E$.
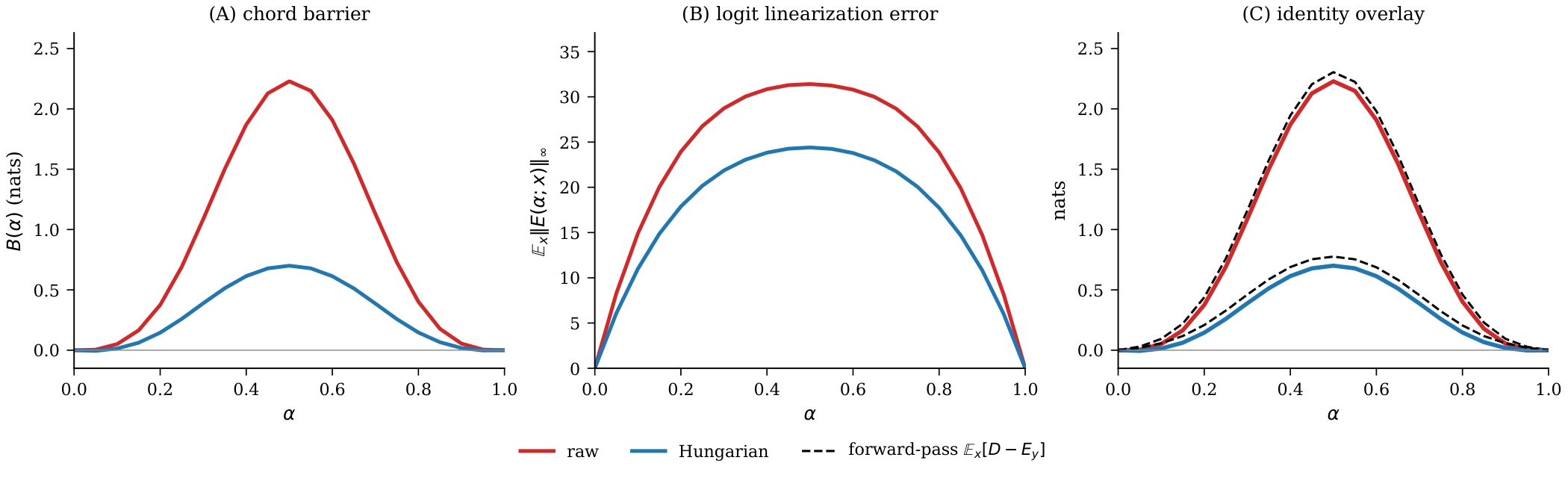
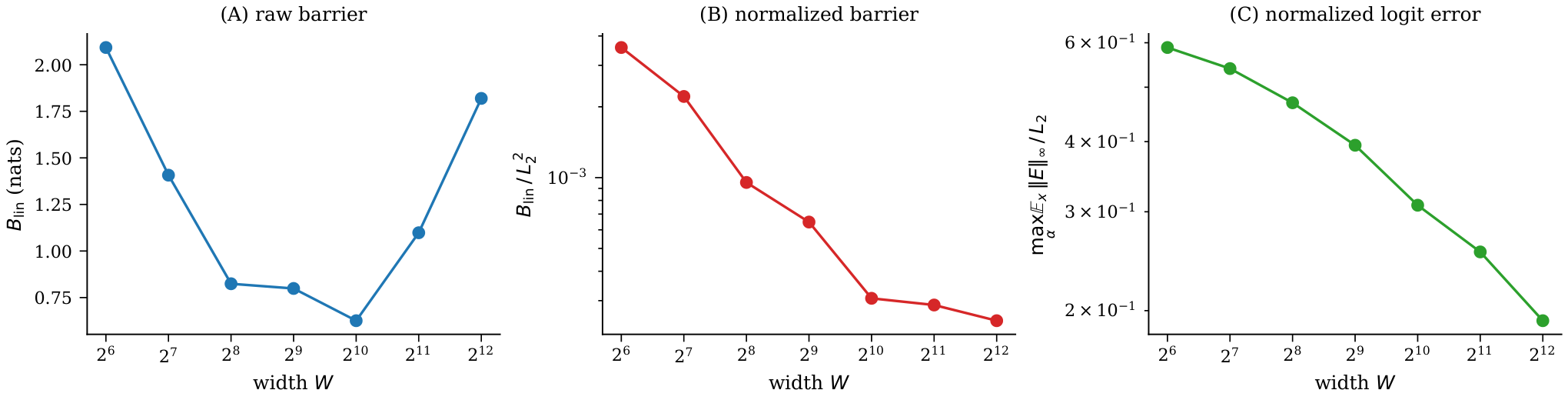
Width and the Near-Linear Regime
As width grows, $E$ shrinks relative to chord length and the normalized barrier $B_{\mathrm{lin}}/L_2^2$ decreases monotonically by 14× from width 64 to 4096.
Barrier Attribution
The decomposition holds per-example, enabling barrier attribution: which inputs, classes, or subpopulations account for the merge gap?
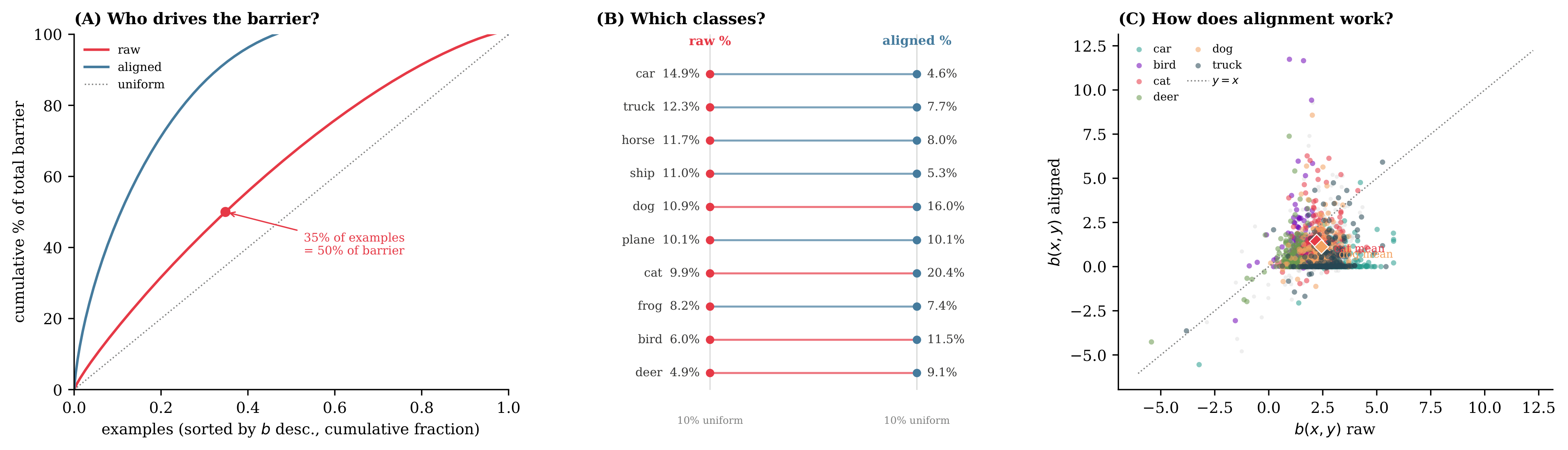
50% of barrier
ratio (max / min)
ranks pairs perfectly
Citation
@inproceedings{bae2026lmc,
title = {Linear mode connectivity barriers are logit linearization gaps},
author = {Bae, Hanbin},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2026}
}